
GenAI: Text 2025
Evaluating the indistinguishability from human writing and the believability of generated narratives.
Notice
Introduction
In recent years, the quality of digital content generated by artificial intelligence (AI) has advanced considerably across various modalities, including image, video, audio, and text. This surge in generative AI capability presents both opportunities and challenges—generative AI has facilitated creative expression and production, enabling artists, designers, and writers to create digital content at a much faster pace, but has also raised concerns regarding the authenticity and integrity of digital media, especially as it has become increasingly difficult to distinguish AI-generated content from human-generated content.
The NIST Generative AI (GenAI) program supports research in generative AI with a structured series of evaluations testing the capabilities of multiple AI technologies in various modalities, beginning with text generation. The 2025 GenAI Text Challenge invites teams from academia, industry, and the research community to test AI capabilities by acting in different roles across the spectrum of AI actors: "generators", "prompters", and "discriminators."
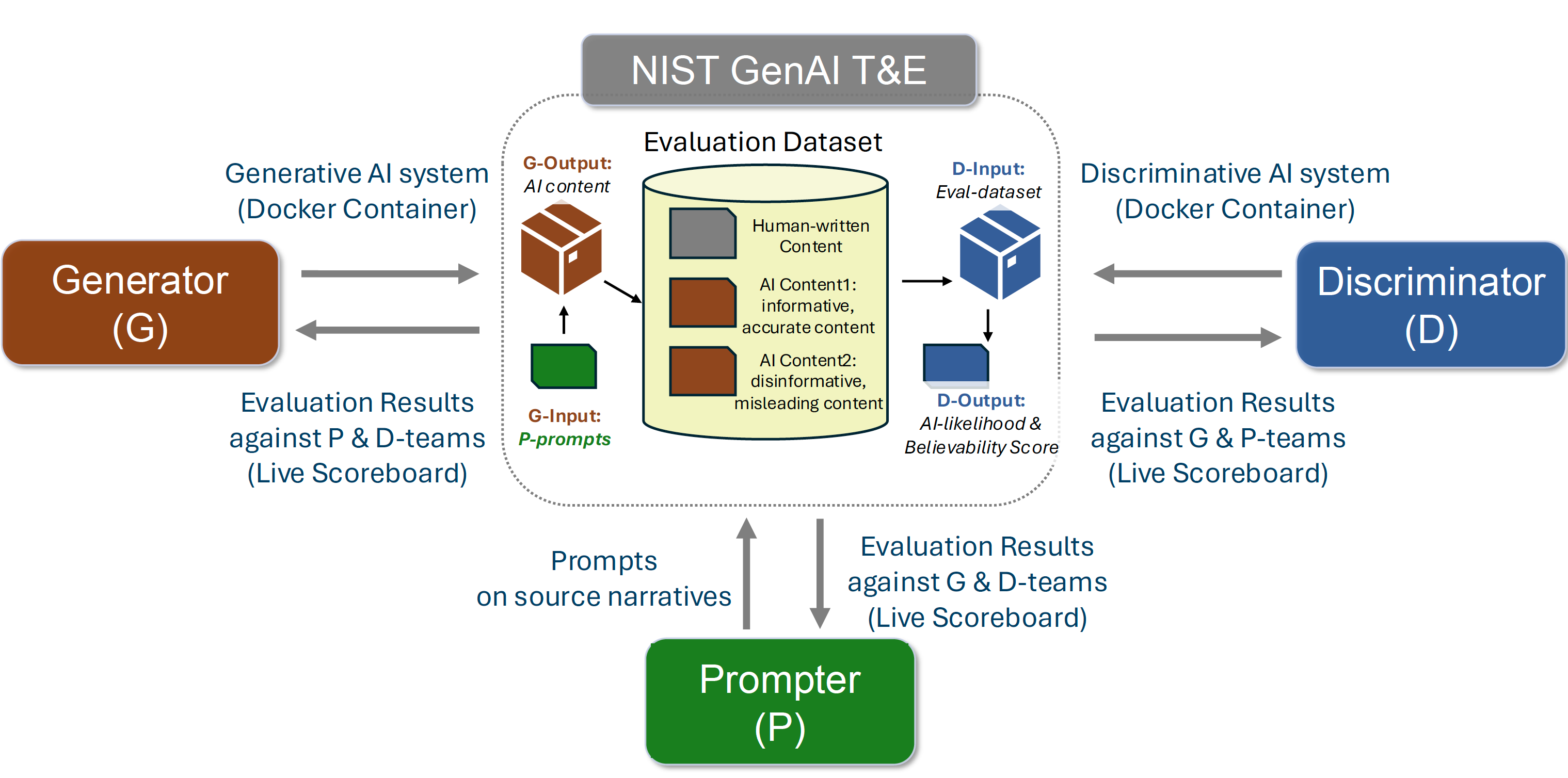
- Generators build AI systems that produce text indistinguishable from human writing. Prompters craft two types of prompts:
- (a) those that elicit accurate, credible narratives; (b) those that elicit intentionally misleading yet believable content.
- The purpose of asking prompters to craft prompts for generative AI models that will produce believable but misleading narratives is that the resulting data can be used to train detectors to recognize such narratives.
- Discriminators create AI systems that classify text as human- or AI-authored and output a believability score estimating the proportion of readers who will believe the text’s main message.
Research Objectives
The purpose of the GenAI Text Challenge is three-fold:
- Evaluate the ability of generative AI models to produce text that is indistinguishable from human writing.
- Assess the effectiveness of AI content discriminators in detecting AI-generated narratives as well as evaluating their believability.
- Explore the ability of prompters to generate credible as well as misleading content.
An analysis of prompting strategies will also help understand factors that influence one to believe in inaccurate or misleading AI-generated content.
Task Coordinator
If you have any questions, please email to the NIST GenAI team
Schedule
|
Date |
Milestone |
|---|---|
|
September 18, 2025 |
Evaluation Plan Posted |
|
January 12, 2026 |
Registration Open |
|
February 20, 2026 |
Registration Close |
|
February 26, 2026 |
Round-table with Registrants |
|
March 30, 2026 |
Dry-run with Sample Set |
|
May 15, 2026 |
Dry-run Close |
|
June 8, 2026 |
Evaluation Start |
|
July 17, 2026 |
Evaluation Close |
Text Generators Overview
Text Generators (Text-G) develop Generative AI models capable of generating high-quality text content. Submissions of the Text-G AI models should be in the form of a Docker container. These models will be used by Prompter teams (Text-P) to generate text content indistinguishable from human writing.
A Text-G is considered successful when it produces content that is difficult for a discriminator (Text-D) to distinguish from human writing. Specifically:
For more details on metrics, data resources, system specifications and requirements, please see the full evaluation plan here.
Text Discriminators Overview
Text Discriminators (Text-D) given a text narrative, which may be AI-generated or human-generated, develop AI models to perform two main tasks:
- Assess the likelihood of the content being AI-generated by assigning a score between 0 and 1 (inclusive), such that scores closer to 1 suggest the content is AI-generated and scores closer to 0 suggest the content is human-generated (0.5 represents total indecision).
- Predict the proportion of the general public that would believe the main message of the text narrative by assigning a believability score between 0 (0% of the public would believe it) and 1 (100% of the population would believe it).
A Text-D is considered successful when it can effectively distinguish AI-generated content from human writing. Indicators of success include:
- AUC-ROC values closer to 1, reflecting stronger discriminative power.
- Brier scores closer to 0, indicating accurate and well-calibrated probabilities.
- Believability scores that correlate well with the proportion of the population expressing high degrees of belief in the main message of the generated content.
For more details on metrics, data resources, system specifications and requirements, please see the full evaluation plan here
Text Prompters Overview
Text Prompters (Text-P) using submitted Text-G AI models and a given topic/source document as input, create two sets of prompts: 1. The first set of prompts should generate accurate, relevant information in a brief, well-organized and fluent manner. 2. The second set of prompts should generate a well-organized and fluent narrative that contains inaccurate, non-credible, and/or misleading information, crafted to be believable to the general public.
A Text-P is considered successful when the prompts it generates lead to convincing outputs from the generator. Success is measured by:
- AUC-ROC values closer to 0.5, indicating that D cannot reliably separate human-written from AI-generated responses. Evaluations will consider the average AUC-ROC across all prompts submitted with a given generator.
- Higher Brier scores, reflecting that D is confidently misled.
- Higher believability scores (close to 1), showing that outputs guided by the prompt are convincing and human-like. Evaluation will consider the maximum and average believability scores across each set of narratives and generator systems, as well as the overall distribution of scores.
Importantly, prompter teams do not generate content themselves. Rather, they influence the quality, credibility, and plausibility of the generated responses through prompt design. Consequently, the evaluation of a prompter system is based on its downstream impact on both generator and discriminator outputs.
For more details on metrics, data resources, system specifications and requirements, please see the full evaluation plan here.
GenAI Text-to-Text Paritipation Rules (Updated: 5/15/2024)
GenAI Text Evaluation Rules (Updated: 5/15/2024)
- Participation in the GenAI evaluation program is voluntary and open to all who find the task of interest and are willing and able to abide by the rules of the evaluation. To fully participate, a registered site must:
- become familiar with and abide by all evaluation rules;
- develop/enhance an algorithm that can process the required evaluation datasets;
- submit the necessary files to NIST for scoring; and
- attend the evaluation workshop (if one occurs) and openly discuss the algorithm and related research with other evaluation participants and the evaluation coordinators.
- Participants are free to publish results for their own system but must NOT publicly compare their results with other participants (ranking, score differences, etc.) without explicit written consent from the other participants and NIST.
- While participants may report their own results, participants may NOT make advertising claims about their standing in the evaluation, regardless of rank, winning the evaluation, or claim NIST endorsement of their system(s). The following language in the U.S. Code of Federal Regulations (15 C.F.R. § 200.113(d)) shall be respected: NIST does not approve, recommend, or endorse any proprietary product or proprietary material. No reference shall be made to NIST or to reports or results furnished by NIST in any advertising or sales promotion which would indicate or imply that NIST approves, recommends, or endorses any proprietary product or proprietary material or which has as its purpose an intent to cause directly or indirectly the advertised product to be used or purchased because of NIST test reports or results.
- At the conclusion of the evaluation, NIST may generate a report summarizing the system results for conditions of interest. Participants may publish or otherwise disseminate these charts unaltered and with appropriate reference to their source.
- The challenge participant agrees NOT to use publicly available NIST-released data to train their systems or tune parameters, however, they may use other publicly available data that complies with applicable laws and regulations to train their models.
- The challenge participant agrees NOT to examine the test data manually or through human means, including analyzing the media and/or training their model on the test data, to draw conclusions from prior to the evaluation period to the end of the leaderboard evaluation.
- All machine learning or statistical analysis algorithms must complete training, model selection, and tuning prior to running on the test data. This rule does NOT preclude online learning/adaptation during test data processing so long as the adaptation information is NOT reused for subsequent runs of the evaluation collection.
- The participants agree to make at least one valid submission for participating tasks. Evaluation participants must do so to be included in downloading the next round of datasets.
- The participants agree to have one or more representatives at the post-evaluation workshop, to present a meaningful description of their system(s). Evaluation participants must do so to be included in future evaluation participation.